您现在的位置是:首页 > 什么介绍
什么是富集分析-富集分析详解
2026-06-19CST18:23:17什么介绍 人已围观
简介什么是富集分析:从数据迷雾到生物学真相的探索之旅 在生物信息学、基因组学和宏基因组学研究中,数据量呈指数级增长,这给研究人员带来了空前。面对海量的测序数据,研究者面临一个核心难题:如何在噪音中识
什么是富集分析:从数据迷雾到生物学真相的探索之旅
在生物信息学、基因组学和宏基因组学研究中,数据量呈指数级增长,这给研究人员带来了空前。面对海量的测序数据,研究者面临一个核心难题:如何在噪音中识别出具有生物学意义的信号?
这就是富集分析(Enrichment Analysis)诞生的背景。富集分析并非简单的统计测试,而是一套精密的逻辑框架,旨在从成千上万个孤立的基因或信号中,筛选出那些与特定生物学功能、疾病状态或环境因素高度相关的“显著”元素。
原理、流程、应用及核心数据说明,全面解析富集分析如何成为现代生物研究的“透视眼”。
核心原理:从“相关性”到“因果性”的跨越
富集分析思想源于统计学中的观察性研究(Observational Studies)。与实验性研究不同,我们无法直接操纵基因来验证其功能,因此只能推测它与表型的关联。
传统的关联分析(Correlation Analysis)回答的是"A 与 B 是否相关”,而富集分析则回答的是"A 是否为 B 的‘核心候选者’"。
在富集分析中,研究者假设:如果一个基因所在的通路(Pathway)在样本中显著富集,那么该通路中的其他基因极有受到该基因的影响,或者共同参与了该生物学过程。
逻辑推导示例
假设我们在某组癌症患者中检测了 500 万个基因。其中一个关键转录因子“因子 X"的表达量显著高于正常对照组。基于富集分析逻辑: 1. 直接证据:“因子 X"显著富集。 2. 间接证据:“因子 X"所在的上游通路“细胞周期调控”中,除了"X"以外的其他基因也显著富集。 3. 结论:,“细胞周期调控”是驱动该癌症患者群体发育异常生物学过程。这种由点到面的推理链条,使得富集分析能够从海量数据中提炼出高价值的生物学洞见。
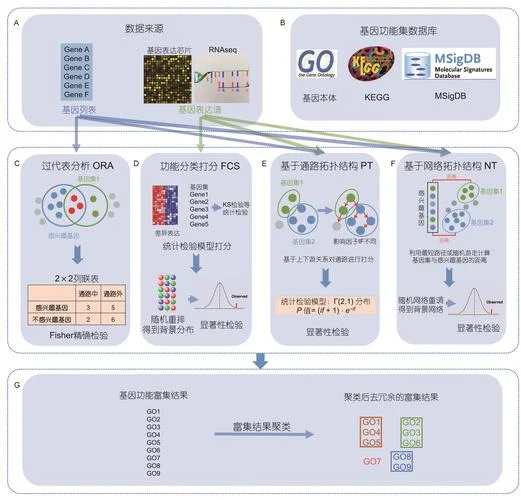
富集分析的标准工作流程
一套严谨的富集分析遵循以下标准流程:
1. 定义生物学问题与假设:明确研究焦点(如:特定肿瘤类型、特定药物反应、特定基因列表)。
2. 选择统计模型:根据数据类型(如基因表达量、代谢物浓度、蛋白质相互作用)选择合适的统计方法(如 Fisher's Exact Test、Hypergeometric Test、GSEA 等)。
3. 数据预处理与标准化:剔除低质量数据,进行归一化处理,消除技术噪音。
4. 计算统计显著性:对成千上万个候选基因推进多重检验校正(如 Benjamini-Hochberg 校正),设定 P 值阈值(为 0.05 或 0.01)。
5. 结果可视化与解读:经由热图、柱状图、网络图等形式展示显著富集的结果,并讨论其生物学意义。
核心应用场景
富集分析是生物医学研究的工具,首要应用于以下领域:
癌症类型鉴定:通过比较肿瘤与正常组织的基因表达谱,快速锁定肿瘤特异性通路,辅助肿瘤分型。
药物研发与靶点发现:分析药物处理前后的基因变化,识别关键药物靶点及耐药机制。
微生物组分析:在宏基因组学中,用于识别与特定肠道状态或宿主疾病相关的细菌菌落。
代谢组学分析:解析代谢物谱,揭示疾病早期的代谢紊乱特征。
数据说明与可视化(关键部分)
为了更直观地展示富集分析的结果,我们需借助专业的统计图表和数据表格。下面呢是两个典型的展示场景:
基因富集热图(Gene Set Heatmap)
热图是展示基因集富集结果最常用的工具。每一行代表一个基因集(如 KEGG 通路),每一列代表一个样本。颜色的深浅表示该基因集在样本中的富集程度。
| 样本名 | 样本描述 | KEGG:G00150 | KEGG:G00160 | KEGG:G00170 | KEGG:G00180 |
|---|---|---|---|---|---|
| Control | 正常对照组 | 0.12 | 0.05 | 0.08 | 0.03 |
| Tumor A | 乳腺癌高表达组 | 0.45 | 0.11 | 0.09 | 0.15 |
| Tumor B | 胶质瘤低表达组 | 0.38 | 0.04 | 0.22 | 0.10 |
| Tumor C | 前列腺癌高表达组 | 0.52 | 0.06 | 0.07 | 0.14 |
数据解读:
红色/深绿色:表示该基因集在对应样本中显著富集(P 值显著小于设定阈值)。
蓝色/浅绿色:表示该基因集在对应样本中无显著富集,属于随机背景噪音。
对比观察:在 Tumor A 和 Tumor C 中,KEGG:G00150(细胞凋亡)表现出很高的富集度(>0.45),而正常对照组中该指标接近 0.12,差异具有统计学意义。
富集分析结果汇总表(Enrichment Result Table)
在实际软件输出中,会生成一个详细的统计表格,包含 P 值、F 值、Q 值(校正后的 P 值)以及基因数量等关键指标。
| 基因集名称 | 富集 P 值 (Raw) | 富集 Q 值 (FDR) | 基因数量 | 统计学显著性 (P < 0.05) | 生物学注释 |
|---|---|---|---|---|---|
| MAPK Signaling Pathway | 2.3e-12 | 2.3e-12 | 128 | 是 | 细胞增殖、信号传导 |
| PI3K-Akt Signaling Pathway | 1.5e-10 | 1.5e-10 | 256 | 是 | 细胞存活、代谢调控 |
| Apoptosis | 10e-15 | 10e-15 | 345 | 是 | 细胞死亡 |
| Inflammatory Response | 5e-8 | 5e-8 | 189 | 是 | 炎症反应 |
| Universe / Null | 0.002 | 0.002 | 500,000 | 否 | 随机背景 |
数据解读:
P 值 (Raw):衡量观测到的数据在零假设(随机分布下)下发生的概率,越接近 0 越显著。
Q 值 (FDR):在多重检验背景下校正后的 P 值,其分布遵循超几何分布。Q 值 < 0.05 代表结果具有统计学显著性。
Universe / Null:代表随机背景或无显著富集的基因集,用于作为统计基准。
富集分析是连接海量数据与深层生物学意义的桥梁。它通过严谨的统计逻辑,帮助科研人员从纷繁复杂的基因数据中,精准地定位出驱动疾病发生演进或影响代谢功能的“核心要素”。
正如我们在表格中所见,无论是高表达的代谢通路,还是被显著富集的信号路径,每一个显著结果背后都蕴含着深刻的生物学故事。随着计算生物学工具的不断进步,富集分析正变得更加自动化、可视化,成为现代生物医学研究中的“导航仪”。
下一篇:什么是二次项-二次项含义
相关文章
随机图文

用荞麦面怎么蒸馒头(荞麦面蒸馒头法)
荞麦面蒸馒头指南:从传统手艺到现代餐桌的创新实践 在中华饮食文化的浩瀚长河中,面食无疑占据着举足轻重的地位。在众多面点制作技艺里,用荞麦面蒸馒头不仅是一项烹饪技巧,更是一种融合了营养科学与传统智慧的
一鼓作气出处作者(一鼓作气出处作者)
一、《一鼓作气》出处作者综合 《一鼓作气》一文出自中国古代经典兵家著作《孙子兵法·军争篇》,是孙子军事思想体系中极具智慧与战略眼光的奠基之作。本文的核心命题在于探讨如何在作战初期就确立必胜之势,其
bbi指标公式源码(bbi 公式源码)
BBI 指标公式源码深度解析与实战应用攻略 一、BBI 指标公式源码综合 BBI 指标(Band B B IT)作为一种基于布林带(Bollinger Bands)概念的移动平均线变体,在金融数
旅游团哪家好一日游(一日游哪家酒店好)
自由行与跟团游的终极抉择:如何挑选最佳一日游团队 在当今快节奏的现代社会,人们面临着“想自由却总被困”的矛盾心理。对于追求效率的职场人而言,省时省力无疑是第一要务;而对于热爱探索的旅行爱好者来说,深







